

AI-摘要
切换
Tianli GPT
AI初始化中...
介绍自己 🙈
生成本文简介 👋
推荐相关文章 📖
前往主页 🏠
前往爱发电购买
Numpy实现神经网络
Hysennumpy实现神经网络
参考教程
弱鸡才用tensorflow,强者一个numpy就够:从零开始神经网络第一期_哔哩哔哩_bilibili
实现
模型示意图:
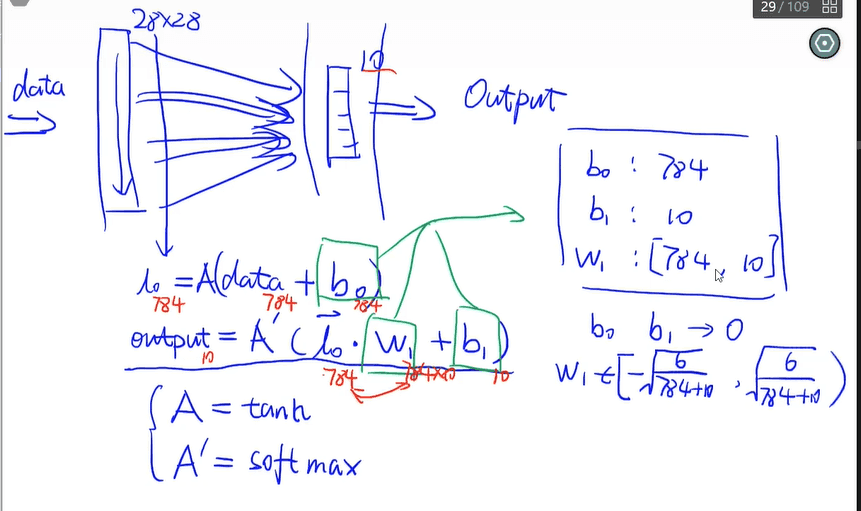
此处给的模型参数:b0 b1 = 0,w1为图片中的范围
激活函数
tanh
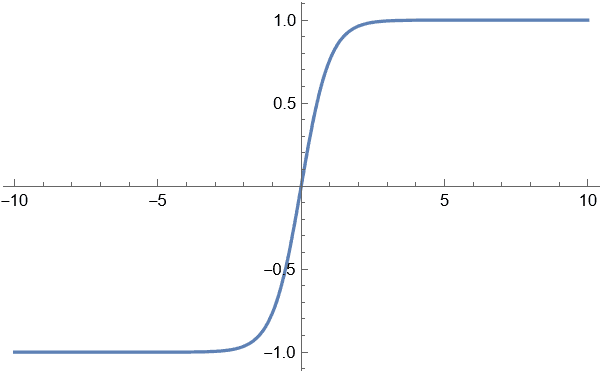
[!bug] 注意
因为激活函数tanh只有在激活区域为[-2,2]的范围内才不为1,当超过这个范围取值都会无限接近于1,而只有在接近于0的时候值才为0,这样在图片数据集取值为[0,255]的无符号8位整型时,==会造成图片二值化的问题,==,即对于一些似黑似白的像素就会全部变成白色,则会更明显的显示图形,训练会出现问题,所以需要在每个图片数据除以255,
softmax
构建模型
读取数据集
数据集网站:
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
下载数据集
在文件夹下新建MNIST文件夹,下载数据集并解压
读取数据集函数
[!failure] 特别傻的错误
要直接把文件解压出来,而不是解压成文件夹,这个是直接读取的文件,而不是文件夹
读取头部数据
struct.unpack('>4i', train_f.read(16)):这是一行代码,它执行以下操作:train_f.read(16):从打开的二进制文件对象train_f中读取16个字节的数据。这表示它尝试读取16个字节的二进制数据。struct.unpack('>4i', ...):使用struct模块的unpack函数来解析读取的二进制数据。具体解释如下:'>4i':这是格式字符串,指定了如何解析数据。在这里:>:表示使用大端字节序(big-endian),即高位字节在前,低位字节在后。4i:表示要解析的数据包含4个整数(i表示整数)。因此,struct.unpack会尝试将16个字节的数据解析为4个整数。
把数据集分为训练集和验证集
==防止过拟合
1 | #把训练集分为两个部分 |
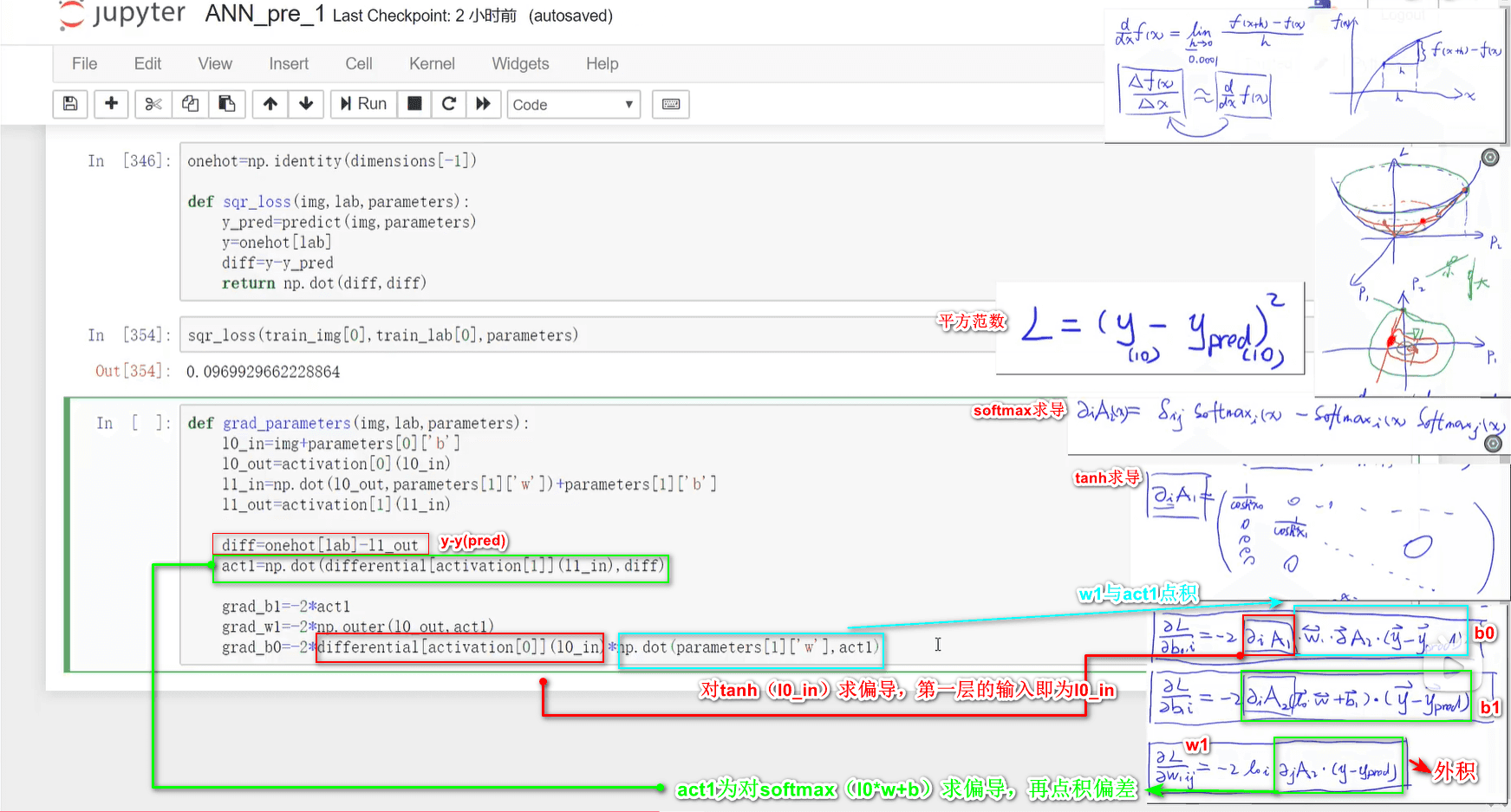
训练
损失函数

喜欢这篇文章的人也看了

评论
匿名评论隐私政策
TwikooWaline
✅ 你无需删除空行,直接评论以获取最佳展示效果





